Kafka - Comunicación asíncrona
Introducción
Como ya vimos en otro blog, gracias a OpenFeign podemos conseguir que los distintos microservicios se comunicaran, esta comunicación es síncrona, en cambio kafka nos otorga una comunicación asíncrona con múltiples beneficios
Porqué usar Kafka
Bueno, y porque no quedarnos con OpenFeign y su comunicación síncrona? Pues por varios motivos:
- Desacoplamiento entre microservicios: El desacoplamiento entre microservicios es un punto muy a tener en cuenta, ya que, pongámonos en el caso de que tenemos 2 microservicios, estos se comunican de manera síncrona con OpenFeign, el microservicio 1 quiere avisar al microservicio 2 de un cambio, y desafortunadamente el microservicio 2 está teniendo problemas de conexión, qué ocurrirá? Principalmente dos cosas
Esperará a recibir respuesta: Esto significa tiempo de espera que afecta al rendimientoSaltará una excepción una vez pasado el timeout: Y sin reintentos (que si son muchos haría la comunicación muy lenta) entonces saltará una excepción sin volver a intentarlo más tarde
- Escalabilidad y flexibilidad: Ahora aparece un microservicio 3, y este quiere ser conocedor también de los cambios del microservicio 1. Pues habría que cambiar el microservicio 1 para que le enviara estos cambios también al microservicio 3. En cambio, con kafka, el microservicio 1 almacenará la información en un topic(que más adelante se explicará que es) y el resto de microservicios estarán en escucha, sin tener que cambiar nada en el microservicio 1. Además que Kafka permite enviar millones de eventos por segundo con latencia mínima.
Estos son los motivos principales, aunque podríamos desarrollar más, y aunque Kafka no solo se usa para microservicios, en este blog nos centraremos en lo que nos atañe.
Arquitectura de Kafka
Y cómo kafka consigue esta velocidad, desacoplamiento y escabilidad? Para responder a esa pregunta necesitamos comprender algunos términos y conceptos clave:
- Producer: Será el que genere los eventos y los publique en un topic de Kafka. En nuestro caso el producer será el microservicio 1
- Eventos: Los eventos son los mensajes que el producer generará, y contendrán esos cambios que el producer quiere notificar:
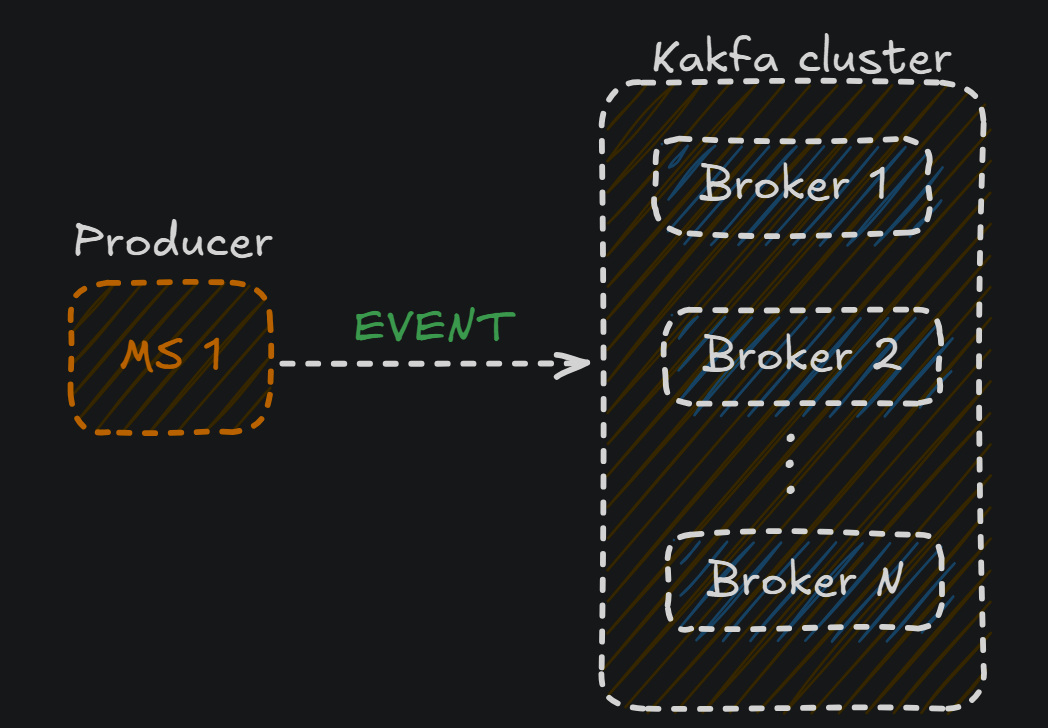
- Broker: El evento enviado por el producer acabará en un broker. El broker será el que recibirá, almacenará y distribuirá los mensajes(eventos)
- Consumer: Este es el microservicio que obtendrá la información(los eventos) publicados por el producer:
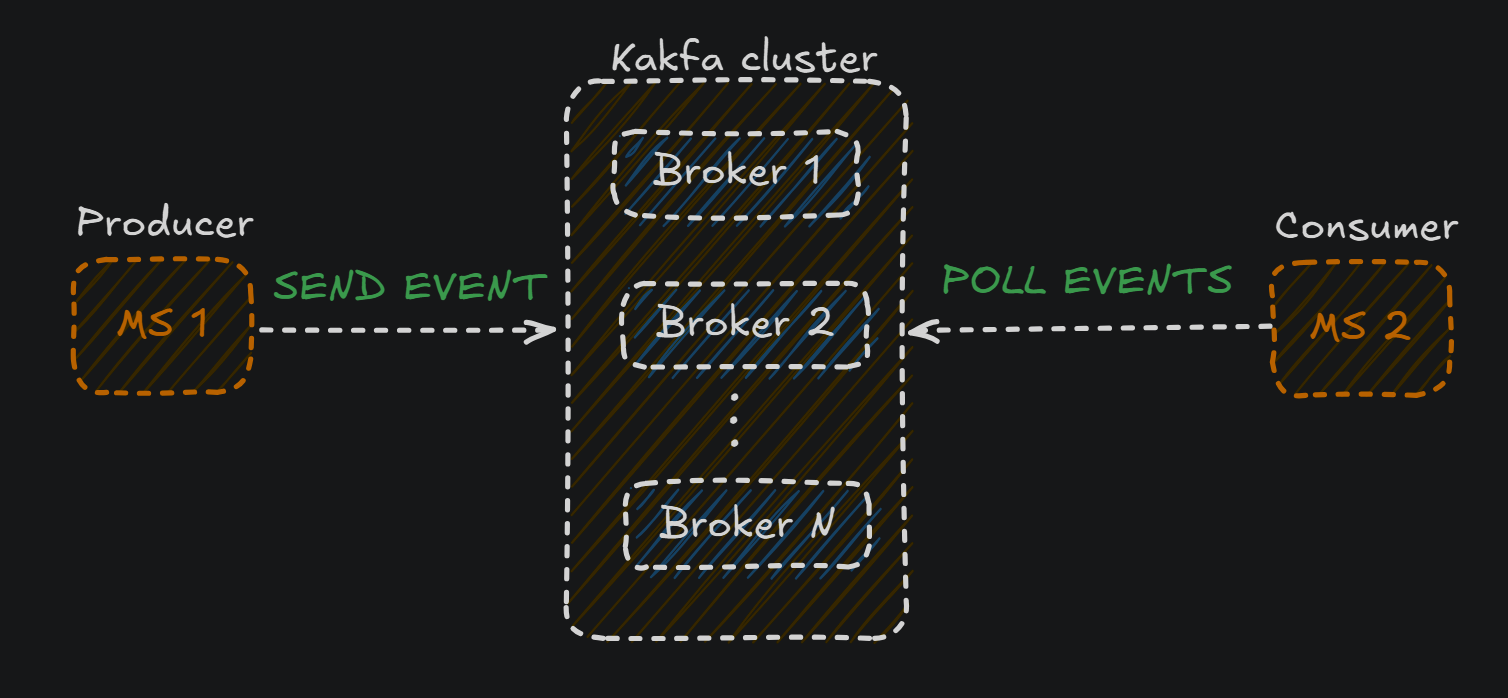
Con esto ya hemos visto a grande escala como funciona kafa en nuestros microservicios, pero la magia ocurre dentro del broker Echémosle un vistazo al interior del broker:
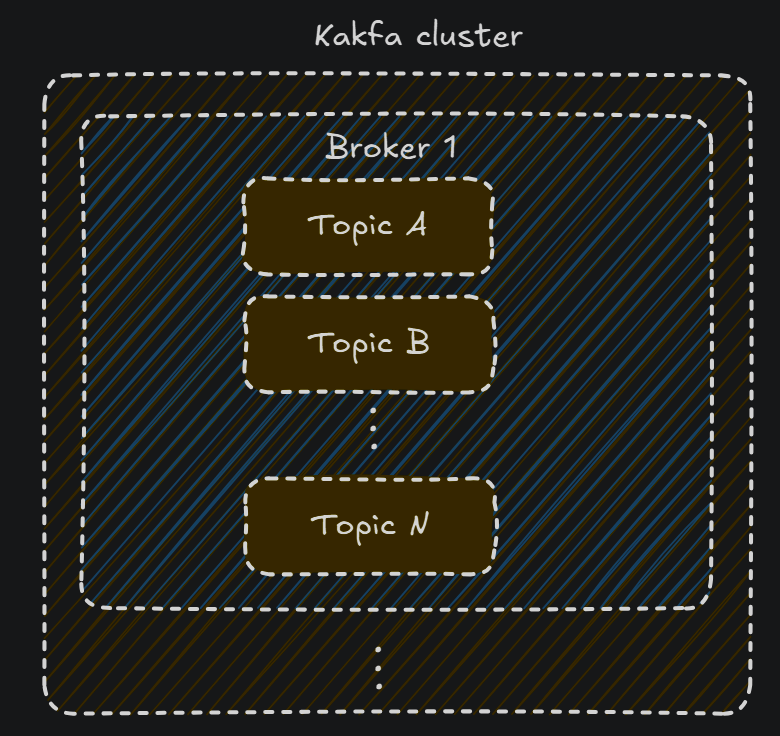 Dentro del broker se encuentra probablemente el término más importante:
Dentro del broker se encuentra probablemente el término más importante:
Los topics: podemos definirlos como las distintas categorías a las que, un producer puede enviar un mensaje(y un consumer leer). De hecho el microservicio no sabrá nada de brokers, lo único que sabe es que quiere subir sus eventos(mensajes) a un topic en específico, y por otra parte, un consumer quiere recibir todos los eventos de un topic en específico. El topic actuará como unlog, almacenando los eventos que los producers hayan notificado, ya que recuerda que pueden haber múltipes producers enviando a un mismo topic, y múltiples consumers cogiendo información de un mismo topic
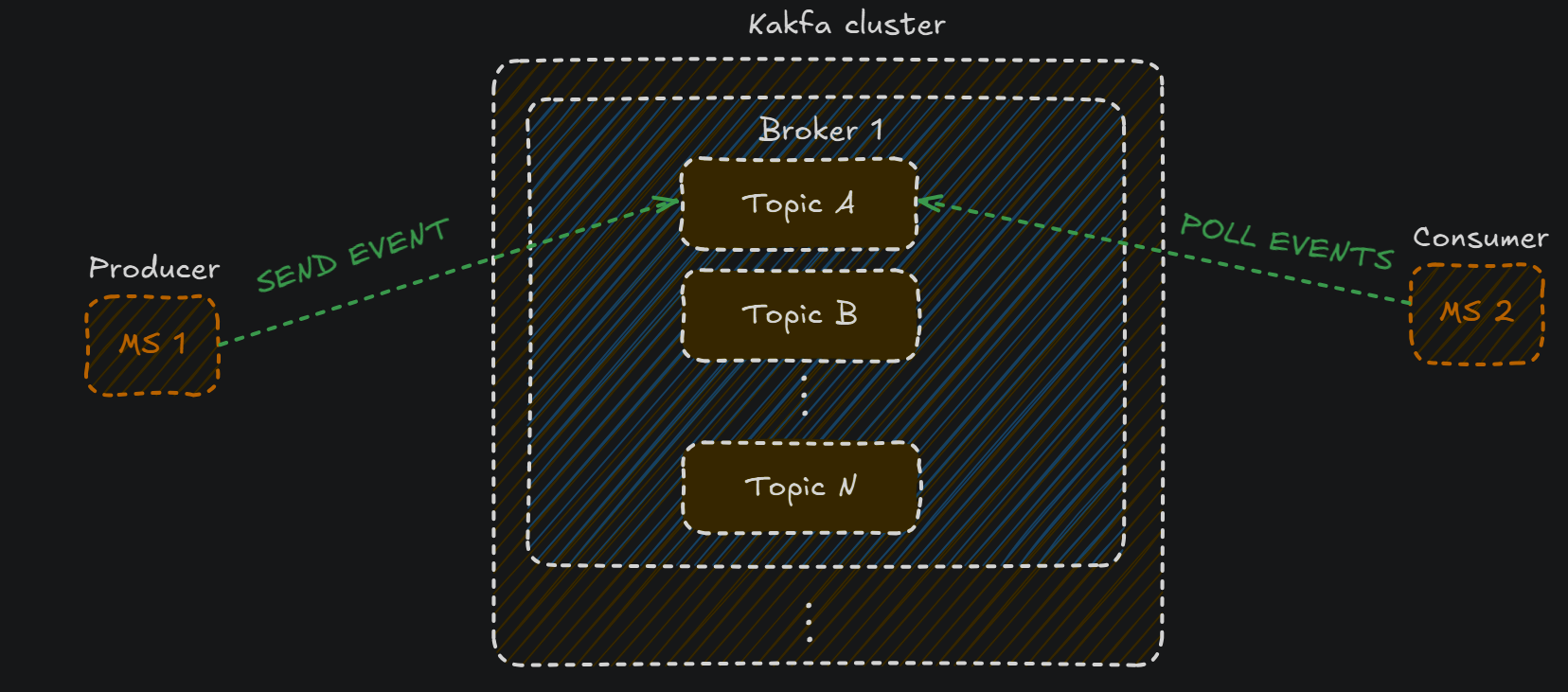
Con esta base ya tienes el conocimiento teórico suficiente para poder utilizar kafka con Spring Cloud Stream(por ejemplo).
Pero parar aquí, supondría quedarse en la superficie, vamos a poner una situación real y ver como se comporta kafka en este caso.
Caso real
Kafka es utilizado para comunicar asíncronamente eventos de manera masiva, por lo que es muy común que un microservicio no tenga una sola instancia.
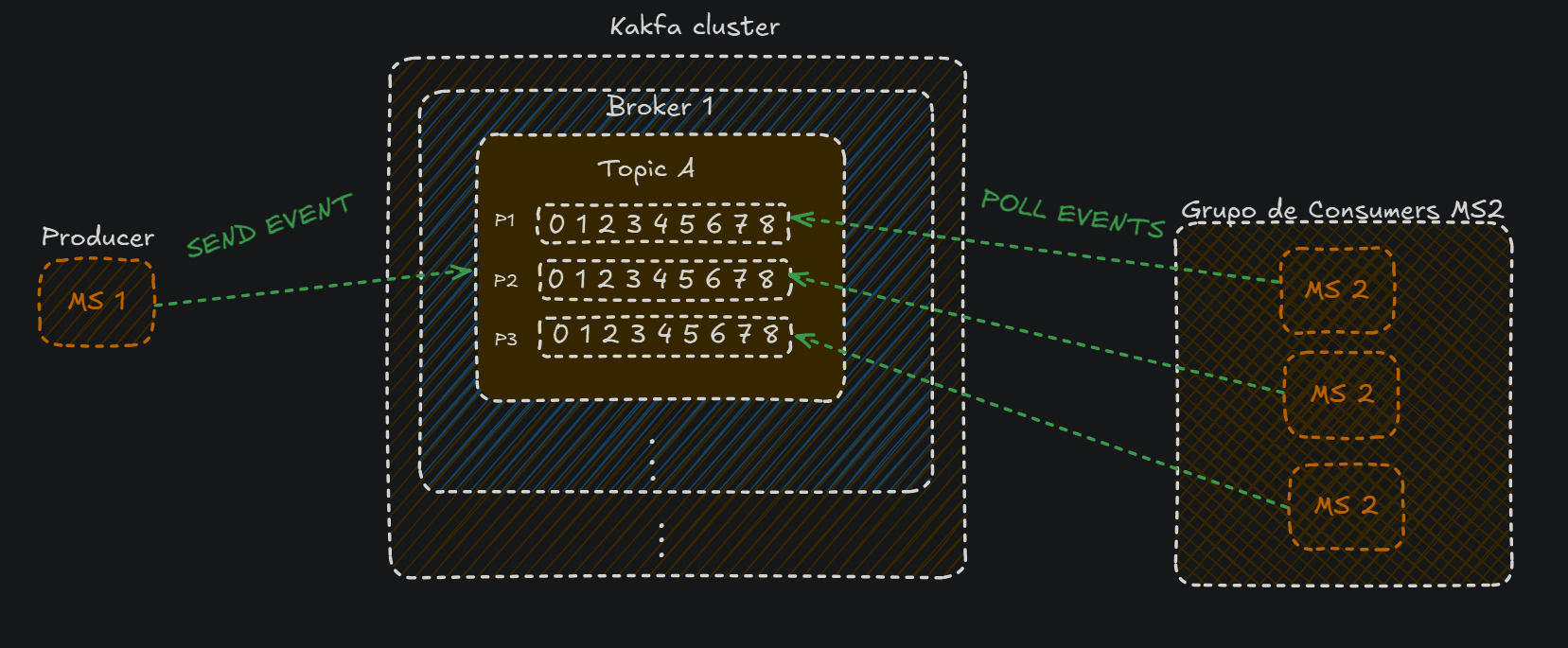
Imagínate que el microservicio 2 tiene múltiples instancias gestionadas con Kubernetes o Docker compose. Estas instancias estarán todas en un mismo grupo de consumers:
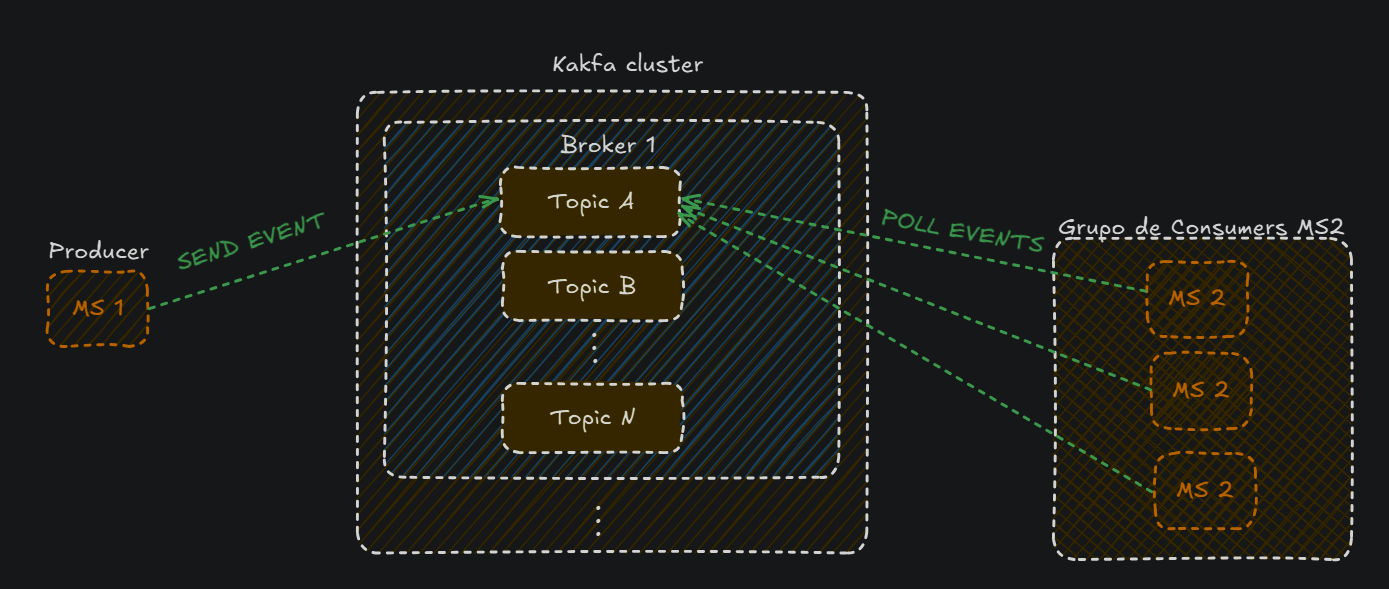 Pero cómo se gestionan para no leer los mismos mensajes?
Esto es gracias a los partitions:
Pero cómo se gestionan para no leer los mismos mensajes?
Esto es gracias a los partitions:
- Los
partitionsson las pequeñas partes en las que se divide un topic, y cada partition tiene que tener un microservicio asignado.
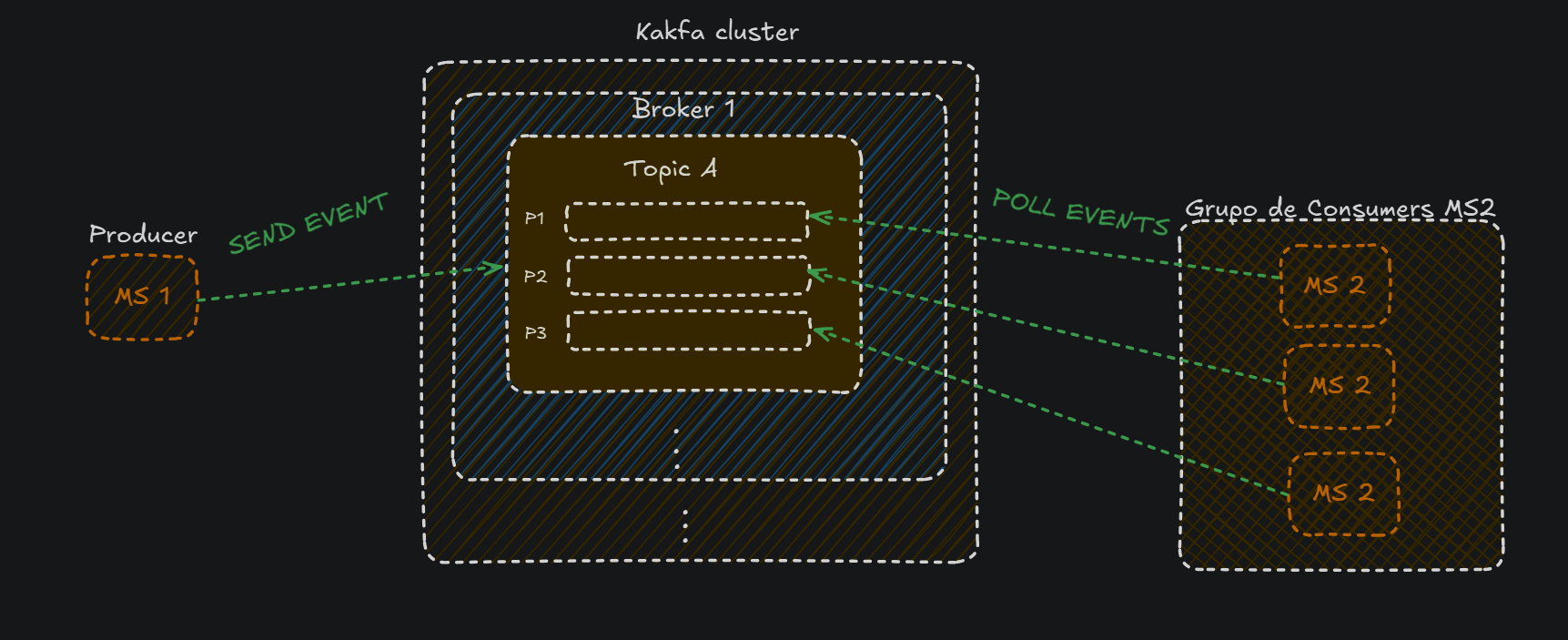
-
Eso sí, una instancia puede tener asignados varios partitions, pero ningún partition puede estar sin conectarse a ninguna instancia, ya que imagina que un partition no está conectado a ningúna instancia y recibe mensajes, estos mensajes se perderían.
-
Los partitions tienen segmentos, como vemos en la siguiente imagen están numerados del 0 al 8(en este ejemplo), y simplemente es una unidad más pequeña de almacenamiento, en la que cada segmento puede almacenar varios mensajes
-
Cada instancia deberá mantener el offset de la partición en la que se ha quedado, y cuando hayan nuevos mensajes, avanzará al siguiente offset.
Resumen
Considero que con toda esta información serás capaz de implementar Kafka sin estar perdido. Kafka es ampliamente utilizado por las empresas, y su presencia en el mercado es casi absoluta. Aunque RabbitMQ también es una opción popular para la comunicación asíncrona, Kafka suele ser la elección preferida cuando se trata de gestionar grandes volúmenes de datos, ya que está optimizado para trabajar a gran escala.
Dicho esto, espero que te haya quedado clara la comunicación asíncrona con Kafka y su potencial. En un próximo blog, explicaré cómo implementar esta maravillosa plataforma de mensajería en un proyecto montado con Spring Boot. :)